At work, we run a simple high-availability (HA) MariaDB setup that consists of an active master that handles all read and write queries from our applications, a passive master that can take over for the active master at any time, and a read-only replication slave (not shown) that we use for backups and analytics.
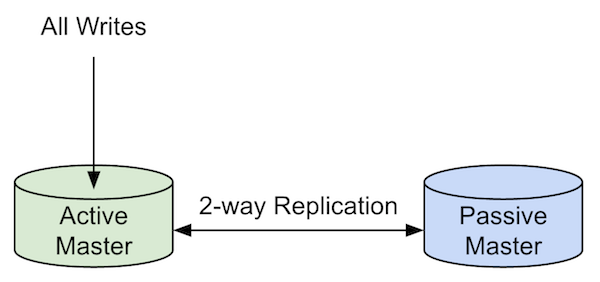
Replication is configured so that the active master follows the passive master, the passive master follows the active master, and the analytics slave follows one of the masters.
For the remainders of this post, I will refer to the active master as the master and the passive master as the standby.
The benefits of this master-master configuration is that it allows us not only to failover from master to standby if the master becomes unhealthy, but also allows us to perform patching, reboots, lengthy migrations, and other kinds of database maintenance without impacting our users. Well, almost...
In the rest of this post I will cover the following:
- Current failover process
- Problems with our current failover process
- A solution to avoid primary key conflicts during failover
- Ideas for potential future improvements
Current failover process
Our current failover process is performed manually by a sysadmin using a checklist. We have two after-hours windows of time every week where we can perform a planned failover. The windows were chosen to coincide with times of low application usage.
- Shut down background worker processes to reduce DB traffic.
- Put the master in read-only mode to prevent any more writes.
- Update internal DNS to route all new connections to the standby. At this point, the standby is the new active master.
- Monitor the old master until we see that it is not receiving any new connections.
- Restart all background worker processes.
This process works well most of the time, but there are several issues that we have encountered during past failovers.
Problem #1: Duplicate primary key errors
During failover there is a small window of time where both the old and new masters could receive writes that result in a duplicate primary key error. While the newly promoted master will work fine, this error silently breaks replication.
SHOW SLAVE STATUS\G
...
Last_Error: Could not execute Write_rows_v1 event on table somedb.some_table; Duplicate entry '996278' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log master-bin.001562, end_log_pos 91239837, Gtid 0-2-833275026, Internal MariaDB error code: 1062
...
If you get this error, your high-availability configuration is broken. You will need to examine the binlogs, analyze the current state of the data on both servers, and perform any necessary reconciliations (either manually or via a one-off script) to ensure you don't lose or corrupt any customer data.
Problem #2: Writes fail in read-only mode
In order to avoid primary key conflicts, we put the master in read-only mode before routing traffic to the standby. This creates a short window of time (usually 5 seconds or less) where writes fail on the master, which results in failed user requests.
Problem #3: Shutting down part of our service
Shutting down background workers to reduce the amount of database traffic during failover only mitigates, but does not eliminate, the potential for primary key conflicts. It also means that part of our service is unavailable for a few minutes, which is something we would prefer to avoid.
Problem #4: Maintenance windows
We would prefer to perform maintenance during regular business hours rather than having to lose sleep or miss out on spending time with our friends and families. Maintenance windows are bad for morale and they are a symptom of deeper technical and organizational problems.
Problem #5: Failover is not instant
While mysql clients in our environment typically detect the internal DNS change in under a second, the change does not take affect immediately.
Solution: Leverage the use of a Virtual IP or HAProxy (or both) to make the cutover instantaneous. There are already plenty of articles online that show you how to do this, so please refer to them at your own risk.
- How to Use HAProxy to Set Up MySQL Load Balancing
- MySQL Load Balancing HAProxy Tutorial
- A More Stable MySQL With HAProxy
- Using HAProxy for MySQL Failover and Redundancy
Problem #6: Multiple manual steps
The failover process consists of multiple manual steps. While we have a checklist to ensure all steps are performed in the correct order, every additional step is an additional opportunity for human error.
Solution: Write a single script to handle the entire failover process, and create a job in our CI/CD server to run the script at the click of a button.
We can do better!
A common theme among all of these problems is that they are mitigations to avoid our #1 problem: primary key (PK) conflicts. How can we accept writes to both masters without creating a PK conflict? If we solve this problem, then we don't have to put the master into read-only mode at all (problem #2), we don't have to shutdown our background workers (problem #3), and we no longer need a maintenance window (problem #4) as we have eliminated the impact to our users entirely.
With a little research, we discovered a very simple solution.
Our new failover solution
- Configure the auto_increment_increment and auto_increment_offset variables on the master such that it only uses odd numbers for auto-incrementing integer primary keys.
- Configure these two variables on the standby such that it only uses even numbers for auto-incrementing integer primary keys.
- Failover write traffic to the standby, promoting it to active master.
- (optional) Set the auto_increment_increment and auto_increment_offset variables back to their original values.
Settings for active master (step #1)
SET GLOBAL auto_increment_increment = 2;
SET GLOBAL auto_increment_offset = 1;
Settings for passive/standby master (step #2)
SET GLOBAL auto_increment_increment = 2;
SET GLOBAL auto_increment_offset = 2;
#winning
The new failover process has fewer steps, is easier to automate (because we don't have to monitor traffic or shutdown background workers), virtually eliminates the possibility of primary key conflicts for auto-incrementing integer values, and can be performed during normal business hours.
Caveats
There are a couple things you should keep in mind when considering this approach.
- Established MariaDB connections will not use the new auto-increment settings. For us this is not a much of a problem because the majority of our database traffic is from the PHP PDO adapter, which establishes a new connection for every transaction.
- There is still potential for a primary key conflict in the event that a long-running write query is taking place during the failover.
Summary
In this post, we examined the naive failover process for an active/passive multi-master MariaDB setup and discussed how improve the process by configuring the servers to use non-overlapping auto increments. We chose to keep things as simple as possible, but depending on your requirements, a solution like MaxScale + Replication Manager or Galera Cluster (which also uses non-colliding auto increment values) may be the better choice for you. As always, do your own research, and make your own decisions.

